这篇采集器爬虫程序实现原理是写给那些觉得采集难,不会使用采集器的人看的,希望你们看了这篇文章后,能够独立使用采集器爬虫程序。当然最终的目的还是为了帮大家省钱,采集规则都能卖钱真的很会玩儿。
作为一个完整的采集网站程序,需要满足两点,第一个是爬数据,第二个是发布数据。这篇文章就先用火车头采集器为例,讲下如何爬取数据,因篇幅问题,发布数据下次再讲。
采集原理
模拟正常请求,以获得服务器返回的数据,然后通过下列手段(但不限于以下手段)获取需要的数据,字符串查找、字符串截取、正则匹配、Xpath规则,json数据解析等。整个采集主要就是找到网络地址规律,拼接地址,模拟访问请求,获得数据,提取数据的过程。
数据来源
采集之初我们需要知道你采集的目标数据从哪儿来的,是网站、小程序还是APP。明白数据从哪里来的,我们才能使用相应的手段获取到数据,为了方便演示,我这里就用最简单的网站数据来源做例子。
采集数据
采集数据的过程其实就是模拟真实请求,以获得数据。但是获得的数据可能不一定就是我们需要的数据,一般我们需要对得到的数据进行处理,特别是网站采集,基本都需要进行处理。
找到采集列表页
当你想采集一个网站的文章时,你需要提供文章地址,但是我们不可能先挨着复制好文章地址再使用软件采集。在网站中,一般都会存在一个列表,这个列表中就是文章的地址,这里我拿dux主题的官网,大前端为例,进行讲解。
采集大前端设计分类下的所有文章,首先找到该分类地址:http://www.daqianduan.com/design,在这个分类地址中,我们可以看到有很多的文章地址,只需提取所有的文章地址,就能进行下一步的内容采集。在这之前,我们还需要找到分类地址中每一页的规律,不然只提供分类的首页地址,我们只能得到大概10篇文章的地址(以分类一页文章数量为准)。
点击大前端设计分类的第二页可以看到其地址为http://www.daqianduan.com/design/page/2,与第一页存在区别,但是,我们修改page后面的页码参数为1仍然能正确访问第一页的内容,因此,我们可以确定大前端dux主题的分类文章列表存在的地址规律是http://www.daqianduan.com/design/page/*
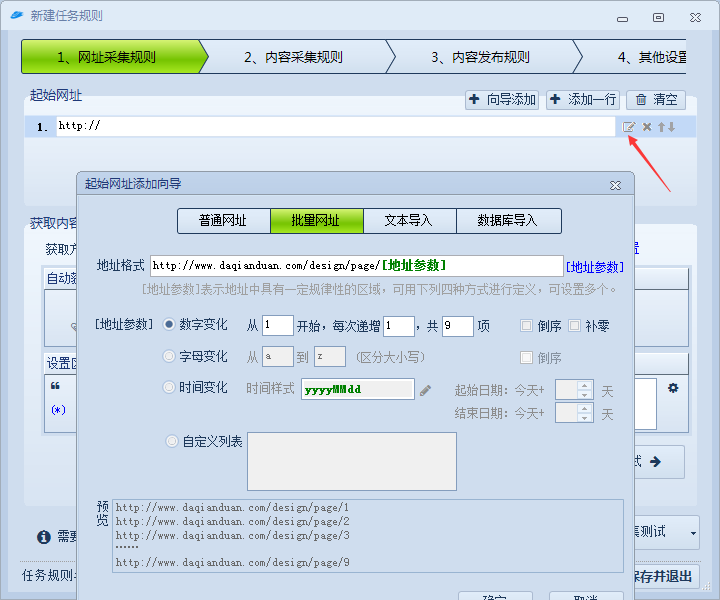
打开火车头,新建一个采集任务,配置分类文章列表网址规则如下:
各种采集器爬虫程序实现原理科普文
地址格式中使用[地址参数]替换掉变化的地方,然后选择[地址参数]为数字变化,目前大前端设计分类总共9页,所以这里我填的9。
获取文章地址
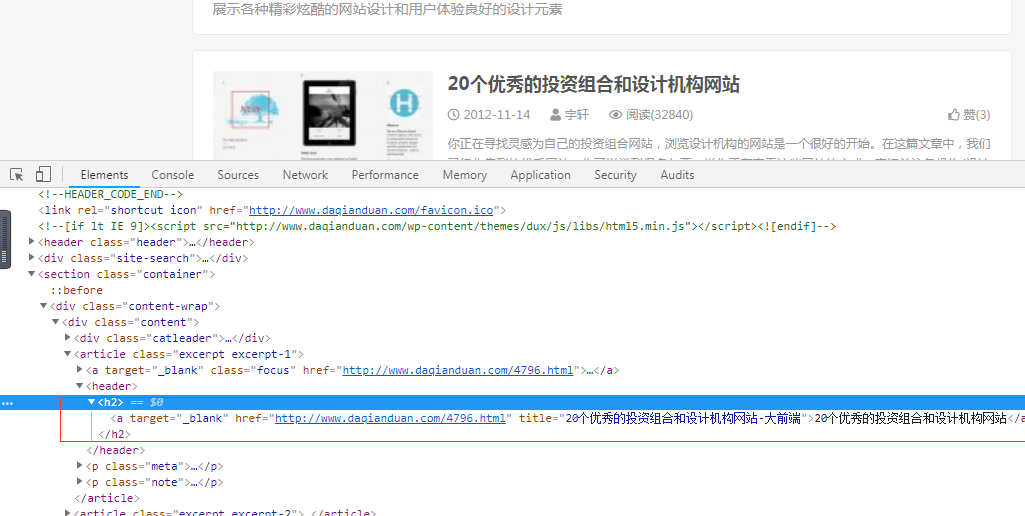
获取文章地址也很简单,在浏览器中使用F12查看文章列表中的文章链接即可,如下:
各种采集器爬虫程序实现原理科普文
这里有个需要注意的地方,我没有使用<a>标签来查找文章地址,是因为,在整个网页中,不只是文章标题会存在<a>标签,为了防止找到我们不需要的地址,这里使用的条件多加上了<h2>标签。火车头规则配置如下:
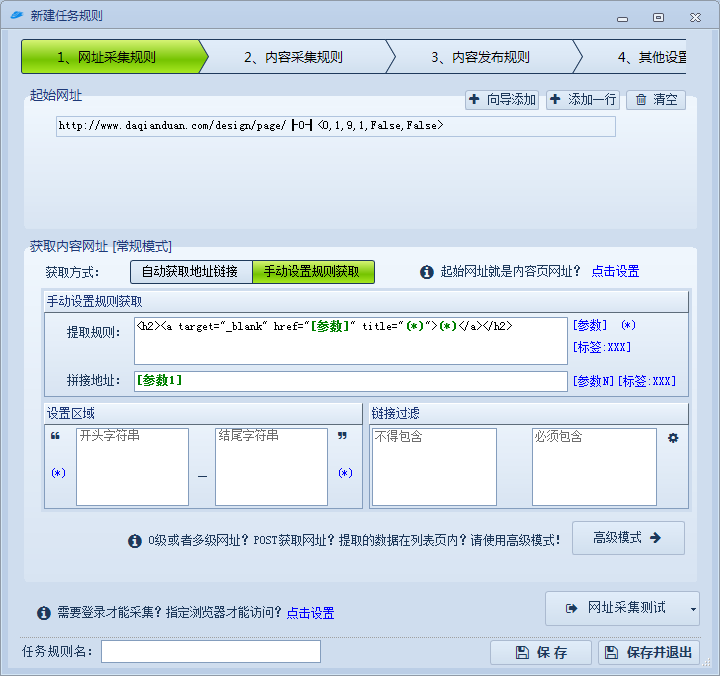
各种采集器爬虫程序实现原理科普文
在获取内容网址下选择手动设置规则获取,自动不一定会找到我们需要的地址,一般选择手动。然后提取规则就是上面红框中的网页结构元素,然后使用[参数]与(*)替换我们需要的东西和忽略的东西,[参数]是我们需要的东西,(*)则表示匹配所有,比如文章标题我们不需要且标题会变化,所以使用匹配所有。
拼接地址那里可以得到提取规则中使用了[参数]匹配得到的数据,比如我上面匹配的文章地址,在拼接地址这里填上[参数1]就会得到提取规则中第一个使用[参数]匹配到的数据。另外,拼接地址可以使用“固定地址[参数1]”形式拼接。比如提取规则那里只取了文章ID,那么在拼接地址这里就应该填上“http://www.daqianduan.com/[参数1].html”。
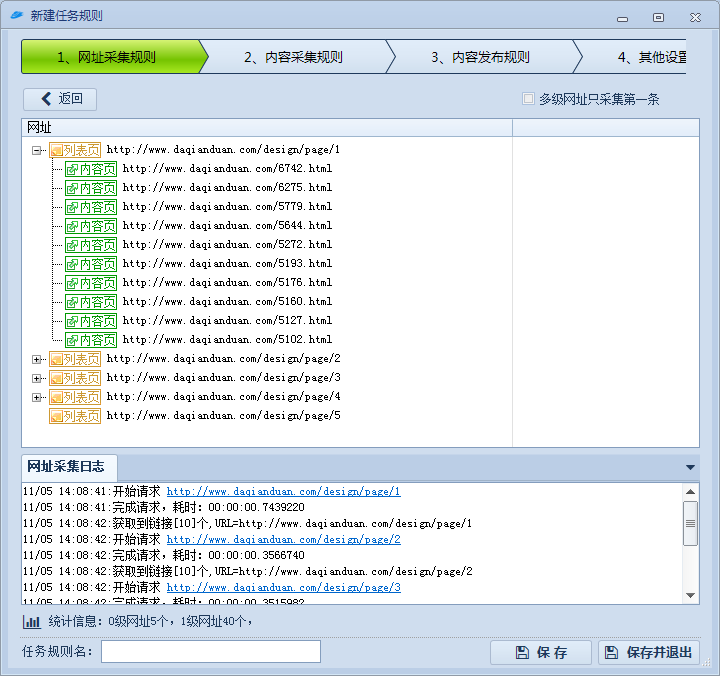
测试采集效果如下图:
各种采集器爬虫程序实现原理科普文
我们已经成功采集到了每一页的10篇文章地址,接下来进入内容采集。
采集内容
采集内容主要有两方面,一是文章标题,二是文章内容。采集原理是,模拟访问文章页,取得文章页所有源码,这个源码就携带了文章内容和HTML标签。然后从源码中提取标题,文章内容。一般有三种提取方式,第一种比较原始,找到唯一字段,然后使用字符串截取来提取目标内容。第二种使用正则来提取,这个方法需要会写正则表达式。第三种比较简单,使用Xpath规则来提取,浏览器自带xpath规则,不需要自己写,但提取失败率较高。
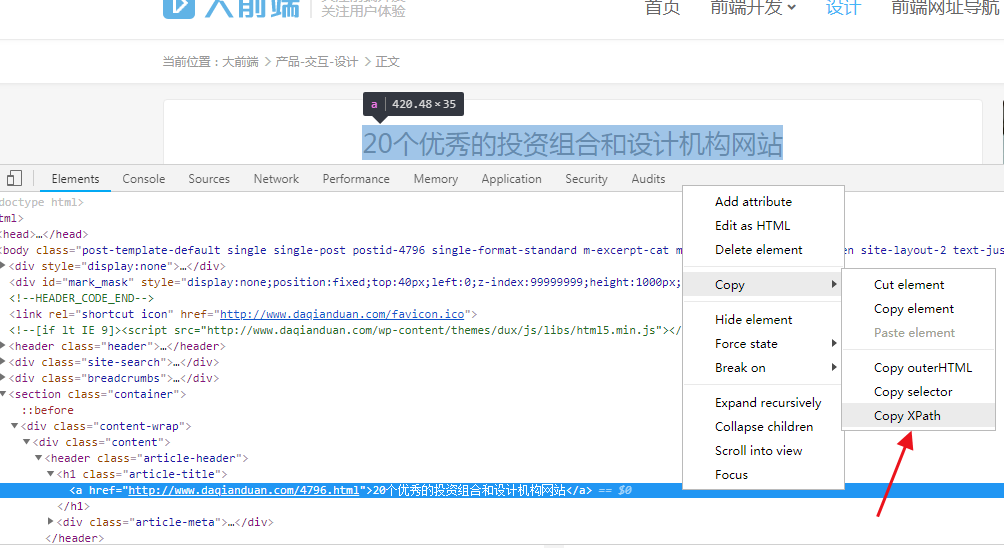
各种采集器爬虫程序实现原理科普文
火车头这边的配置如下:
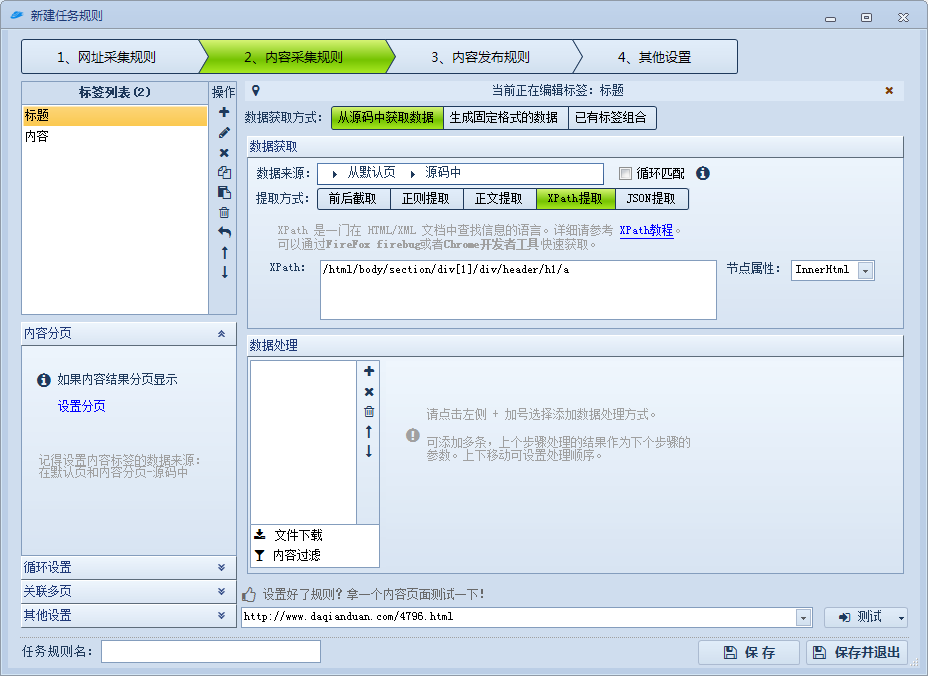
各种采集器爬虫程序实现原理科普文
填好规则后,可以使用下面的测试,试试提取的内容有没有问题。
内容采集规则也是一样,这里就不多赘述了。
当你采集的内容中有不需要的或者需要替换的,可以使用替换规则,修改即可。
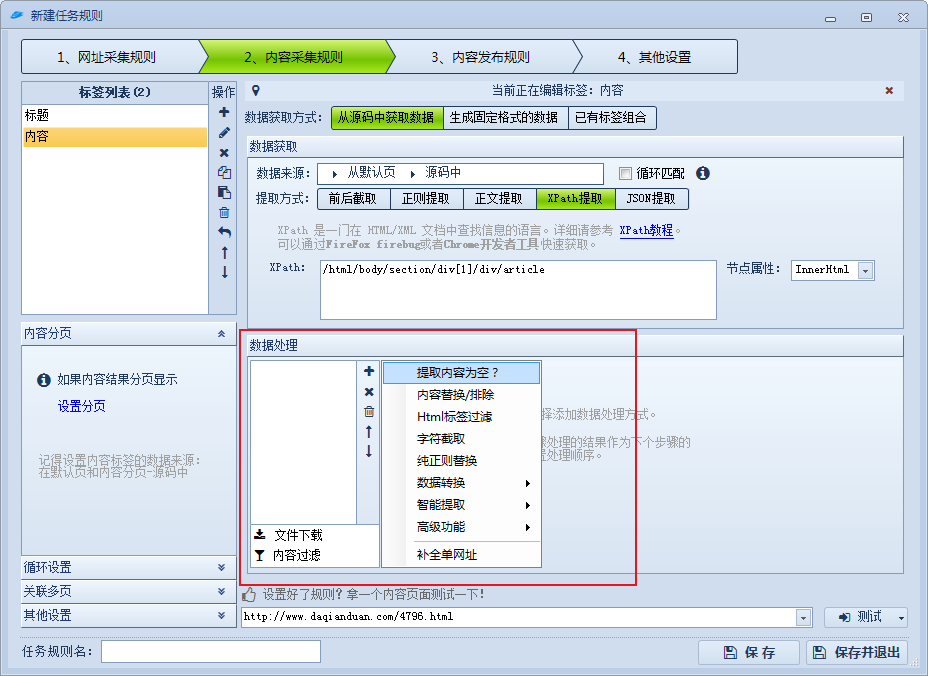
各种采集器爬虫程序实现原理科普文
这些功能部分收费,火车头采集器V9无限制版本分享,免费工具提供给大家使用。采集部分就到这里了,下一章讲发布规则。





评论 (0)