其实图片的文字识别其实还算简单,一般是根据特定字体制作出字码文件,然后分割图片比对字码,这种方式在易语言中比较常见,一般用来做游戏脚本。OpenCV也提供了OCR文字识别函数,并且还是跨平台的,不过一般人很少用。使用腾讯AI开放平台api进行图片OCR文字识别可以在不了解OCR文字识别原理的情况下进行,用户只需要提供图片,一切都由腾讯计算完成,大大降低了识别门槛,下面一起来试试。
首先你需要注册腾讯AI开放平台的账号,并且创建一个应用,这样你才能得到APPid与APPkey,不然进行不了下一步。
腾讯AI开放平台地址:https://ai.qq.com
下一步就是为你创建的应用接入通用OCR识别能力,只需要在后台通用OCR项目中点击接入能力按钮即可。
为了方便,我这里使用PHP来识别一张图片,图片也是我直接截图通用OCR的说明,如下。
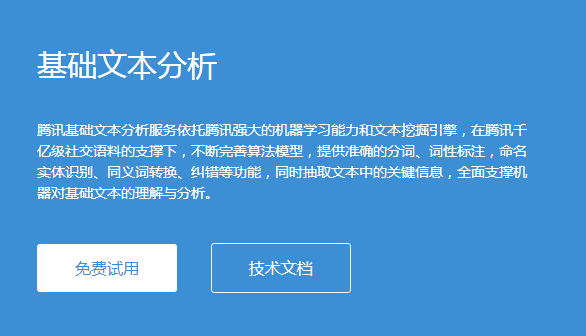
使用腾讯AI开放平台api进行图片OCR文字识别
看看全部代码:
复制
<?php
//ocr请求地址
$url='https://api.ai.qq.com/fcgi-bin/ocr/ocr_generalocr';
$app_id = '你的appid';
$app_key = '你的appkey';
//请求参数
$params = array(
'app_id' => $app_id,
'nonce_str'=>uniqid("{$app_id}_"),
'time_stamp'=>time()
);
//读取待识别图片
$image_data = file_get_contents('./20190517203050.png');
//编码后加入到请求参数中
$params['image'] = base64_encode($image_data);
//计算签名,并加入到请求参数中
$params['sign'] = getReqSign($params, $app_key);
//发起post请求
$response = json_decode(doHttpPost($url, $params));
//解析结果
if( $response->msg=="ok"){
$data=$response->data;
$item_list=$data->item_list;
for($i=0;$i<sizeof($item_list);$i++){
echo $item_list[$i]->itemstring."</br>";
}
}
//post请求方法
function doHttpPost($url, $params)
{
$curl = curl_init();
$response = false;
do
{
curl_setopt($curl, CURLOPT_URL, $url);
$head = array(
'Content-Type: application/x-www-form-urlencoded'
);
curl_setopt($curl, CURLOPT_HTTPHEADER, $head);
$body = http_build_query($params);
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $body);
curl_setopt($curl, CURLOPT_HEADER, false);
curl_setopt($curl, CURLOPT_NOBODY, false);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 2);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
$response = curl_exec($curl);
$_http_code = curl_getinfo($curl, CURLINFO_HTTP_CODE);
if ($_http_code != 200)
{
$msg = curl_error($curl);
$response = json_encode(array('ret' => -1, 'msg' => "sdk http post err: {$msg}", 'http_code' => self::$_http_code));
break;
}
} while (0);
curl_close($curl);
return $response;
}
//计算签名方法
function getReqSign($params, $appkey)
{
ksort($params);
$str = '';
foreach ($params as $key => $value)
{
if ($value !== '')
{
$str .= $key . '=' . urlencode($value) . '&';
}
}
$str .= 'app_key=' . $appkey;
$sign = strtoupper(md5($str));
return $sign;
}
?>整个过程分为计算签名、封装请求参数、发起post请求、解析返回结果四个部分,上面的代码写得很清楚。但是有个值得注意的地方,在计算签名的时候一定要在发起post请求的前一步进行,不然会出现无效签名的错误。这个情况应该是腾讯在对请求参数中的时间戳限制过于严格导致,因此尽量减少时间戳与发起请求时间之间的误差即可解决。
解析后的效果:
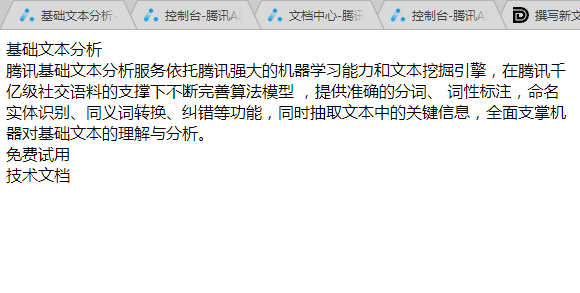
使用腾讯AI开放平台api进行图片OCR文字识别
除了排版有问题之外并没有什么大问题,如果你需要排版也是可以的,解析结果中有每个字符所在的坐标。
总的来说整个识别流程还是非常简单的,比自己写OCR识别算法简单多了,缺点就是整个识别流程太耗费时间,大部分时间都消耗在了网络传输中。最后不得不吐槽一下腾讯的PHP demo,使用的开发环境太古老了,一大堆的异常,虽然不影响使用。





评论 (4)