前面讲了C#单线程查询网站百度收录情况,C#实现查询网站地图中链接的收录情况源码分享。单线程有个很明显的缺陷,如果查询数量太大,耗费的时间超乎想象,为了节省时间,我们可以采用多线程的方式,并发处理,将单线程的等待时间大幅度减少,达到节省时间的目的,接着上次的源码,简单讲一下这次的多线程与单线程在代码方面有哪些区别,文末会给出完整代码并附带编译好的程序。
先看看单线程与多线程查询的耗时:
单线程耗时,244秒左右。
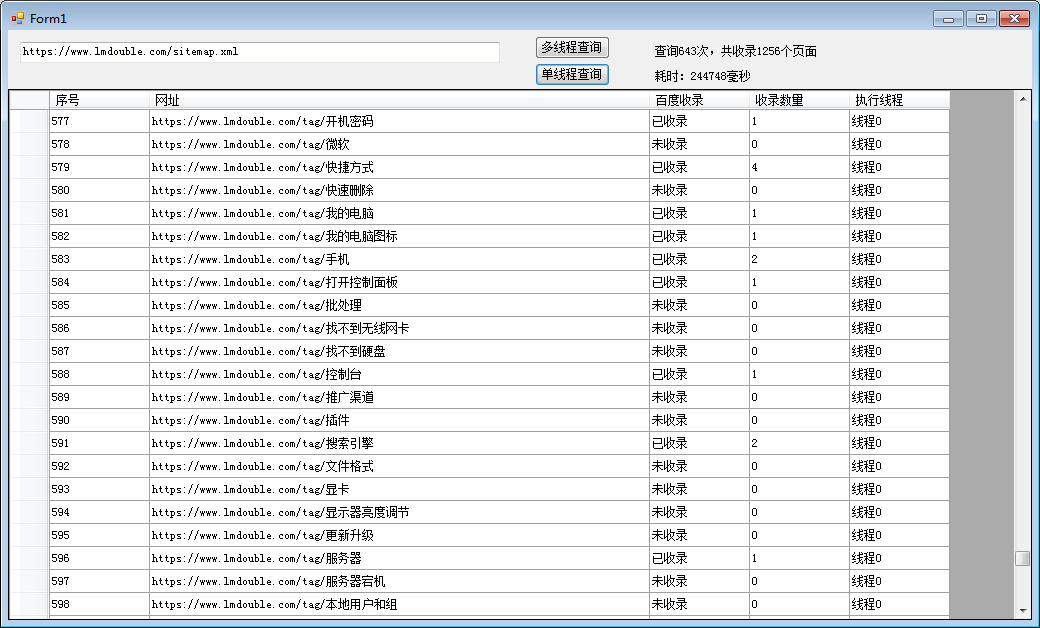
C#单线程查询网站百度收录情况源码
多线程耗时:69秒左右。
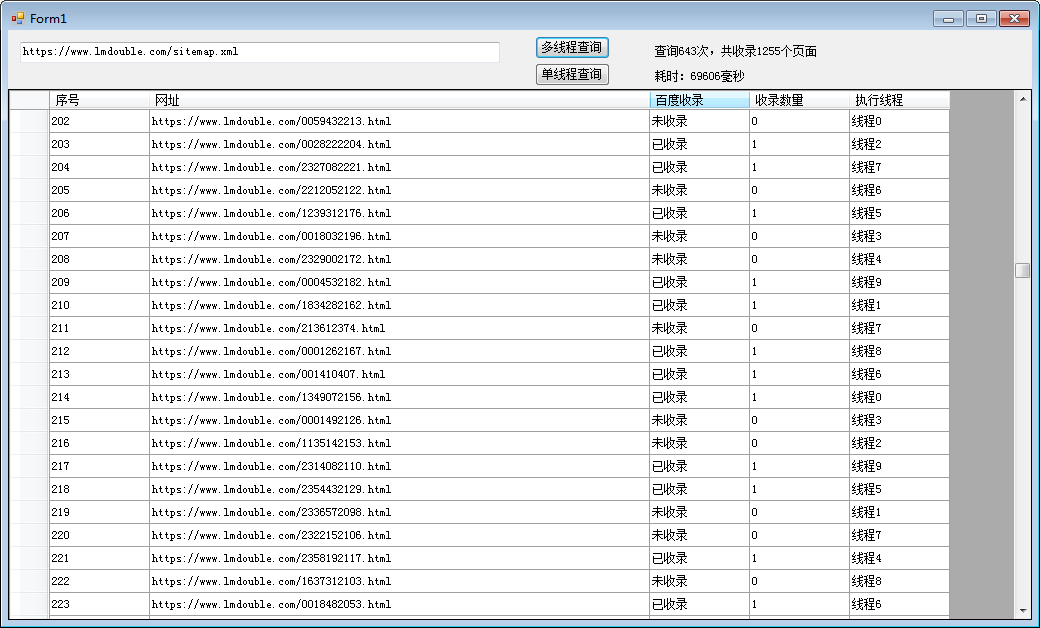
C#多线程查询网站百度收录情况源码
很明显的区别,节省了3倍多的时间。多线程我用的10个线程。不要认为线程越多节省的时间越多,这个最佳线程数量有兴趣自行测试。
单线程就不讲了,前面已经说得很清楚了,下面讲讲多线程处理数据时最重要的东西,线程锁。
lock (object)
{
//数据处理
}上面的object可以是自己定义的,也可以是this关键字,但不能是null对象。
当一个线程执行到lock时,它将检查是否存在lock锁,如果存在,则等待lock内容执行完毕。如果不存在,则申请lock锁,并执行。
重点来了,我们查询百度收录情况时,耗时操作基本都在网络访问过程中,因此,我们在lock中只需要处理好被访问的url即可。然后迅速解锁,将url传给访问网页的方法,并让下一个线程获取url数据,这样既确保了url的不重复性,又将耗时操作分摊给10个线程。也就是说,多线程查询10次使用的等待时间与单线程1次查询等待时间一样(不考虑网络环境影响)。
当数据被处理完成后,我们可以使用线程的Abort方法结束线程。
为了在清楚直观的看到是哪个线程在处理数据,我们可以在线程中使用Thread.CurrentThread方法获得当前线程对象,然后通过线程对象的Name属性取得线程名称并使用委托方法显示到UI界面上。
注意:C#的lock锁一定要包裹被锁定的数据,不然会错乱!多线程应用在大量数据中效果明显,少量数据中区别不大,我使用的这个例子只有600多个页面,因此只体现了3倍多的差距,大家可以试试大量查询的时间差距!





评论 (2)